ENRICHED METADATA CATALOG
Metadata is the heartbeat of intelligent data management
At the core of successful data management lies metadata—the key to understanding what you have and act on it with confidence. Diskover transforms massive amounts of unstructured data into living intelligence fueling automation, analytics, and AI-powered insights.
Ask your metadata about your data.
Metadata is the “who, what, where, when, and why” behind every file. It’s the connective tissue transforming raw, unstructured data into context-rich assets. By centralizing and enriching metadata, organizations gain the clarity to discover insights faster, automate workflows, and power AI-driven decisions with confidence.
Turns chaos into clarity.
Metadata connects every file to its story—who, what, when, and why—giving organizations clarity and control across silos.
Strengthens trust.
Metadata enforces retention, access, and audit rules—keeping your data compliant, accountable, and always inspection-ready.
Drives precision.
Metadata tracks every simulation, version, and dependency—ensuring traceability, accuracy, and faster verification cycles.
Streamlines workflows.
Metadata follows assets from shoot to screen, automating QC, versioning, and asset preservation for seamless post-production.
Automates data lifecycle.
Metadata-driven orchestration synchronizes your entire data lifecycle—moving, cleaning, and optimizing datasets.
Amplifies intelligence.
Rich, structured metadata transforms raw data into curated datasets that train models, accelerates insights, and drives innovation.
Accelerates discoveries.
Metadata links experiments, samples, and instruments, making genomic and clinical data searchable, reproducible, and AI-ready.
Fuels exploration.
Metadata unifies seismic, sensor, and production data—enhancing asset tracking, compliance, and operational efficiency while reducing storage costs.
How it work—from scattered files to a metadata catalog.
Diskover transforms simple file attributes into a living metadata ecosystem. As data is indexed, context is harvested from filenames, directory structures, and plugin enrichments—creating a searchable, reportable, and actionable metadata catalog.
This living metadata ecosystem gives teams full control to automate policy-driven workflows, prepare AI-ready datasets, and maintain governance across every storage environment.
Enrichment plugins add business context to your catalog.
A metadata catalog is the central hub for complete data control.
Data lineage—your data’s story matters more than its zip code.
Diskover uses metadata to map relationships across your data estate—so you can trace where data came from, how it changed, where it lives now, and what depends on it.
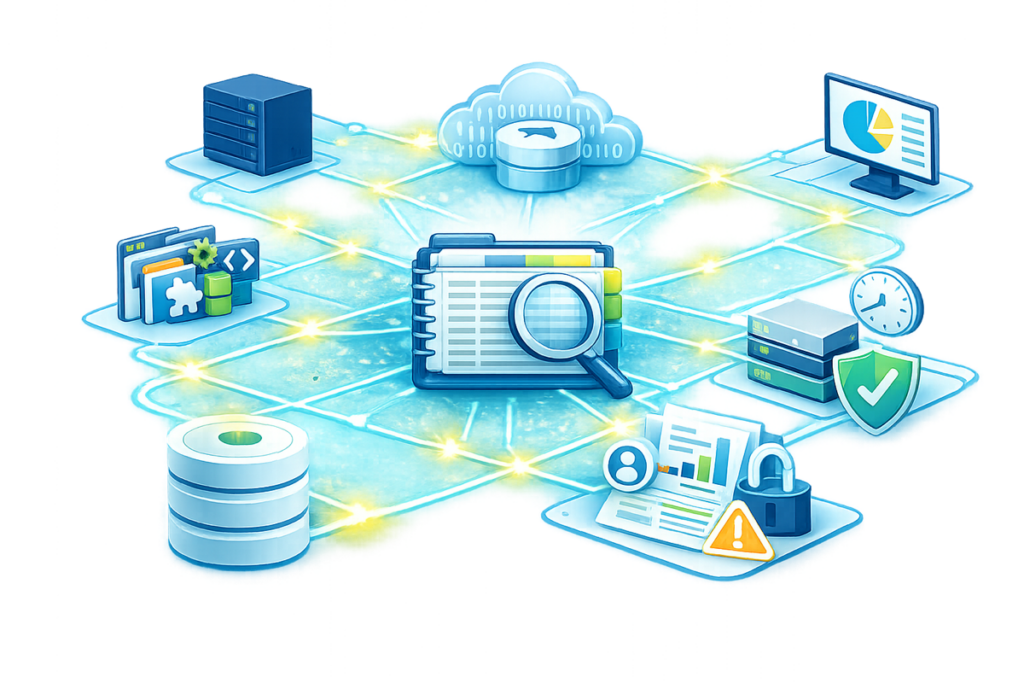
How tagging extends your metadata catalog.
Tagging adds a flexible classification layer to your metadata catalog. Diskover supports both user-driven tagging and automated tagging policies—allowing assets to be grouped, searched, and managed according to business logic, project workflows, or lifecycle rules.