INTELLIGENT DATA MOBILITY FOR REAL-WORLD WORKFLOWS
Right data. Right place. Right cost.
We transform data mobility from a reactive task into a proactive, intelligent process. Whether triggered manually or automated by policy, every move is driven by metadata insight—so files go exactly where they should, when they should, with full cost awareness. The result: lower spend, better performance, and faster, safer lifecycle decisions.
Move data confidently—with context and control.
Modern data estates demand more than storage—they require intelligent movement. Tiering and lifecycle automation keep data aligned to value and purpose, moving seamlessly across hot, warm, and cold tiers. With metadata-driven rules and policy automation, teams can retain, archive, or delete data by age, cost, and usage—improving efficiency and compliance while protecting data throughout its lifecycle.
Automate your data tiering.
Keep your storage footprint and spending in check.
Tiering ensures data lives on the right tier at the right time. High-performance workloads stay on fast flash storage, while less active or archival data automatically flows to lower-cost tiers — maintaining an optimal balance between speed, accessibility, and cost efficiency.
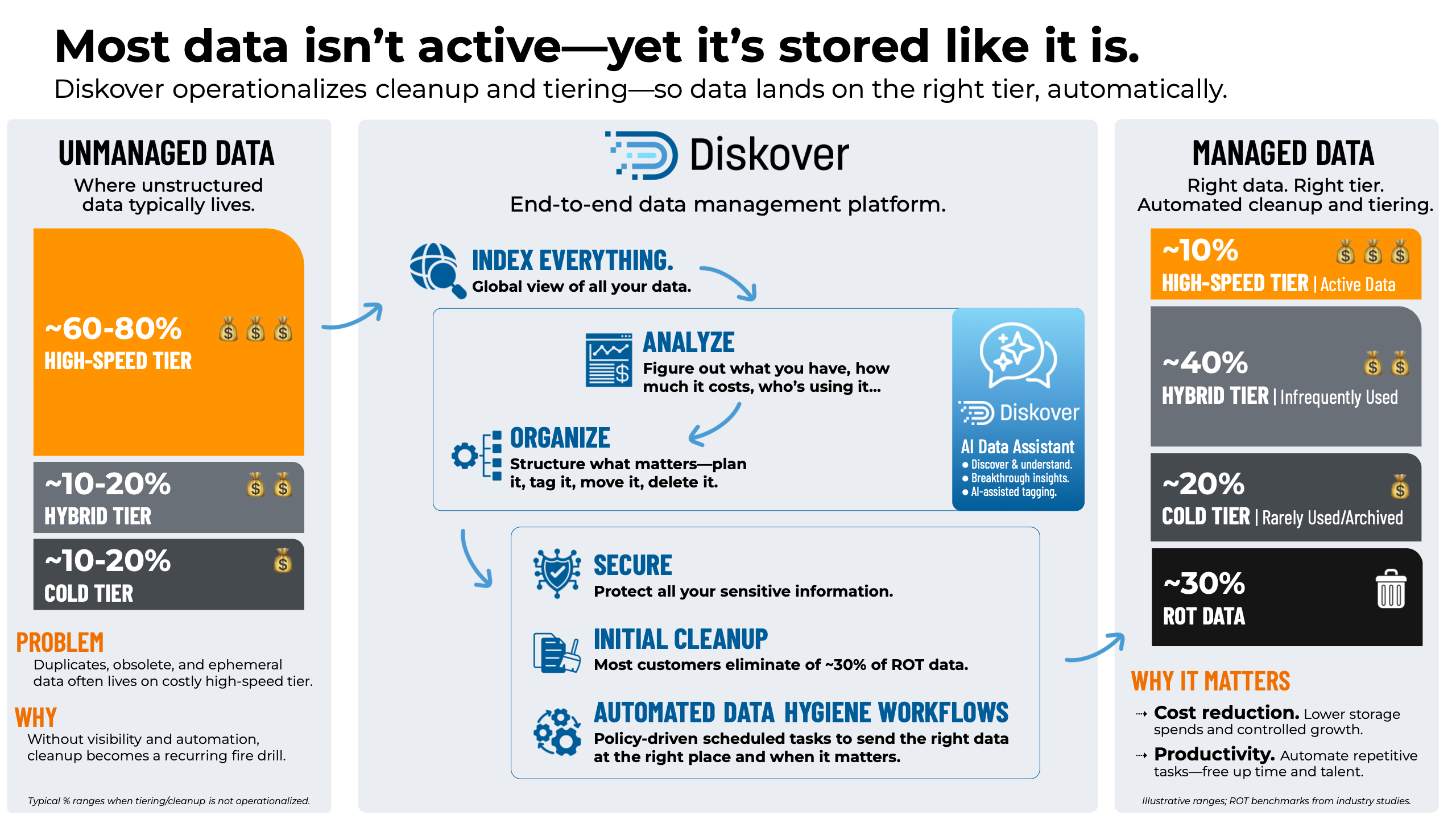
Automate your data lifecycle.
Turn lifecycle workflows into measurable end-to-end wins.
Lifecycle automation takes data beyond simple storage. From creation to archival or deletion, data moves intelligently based on policies and business workflows—ensuring compliance, maintaining protection and recoverability, reducing manual intervention, and keeping infrastructure clean and sustainable.
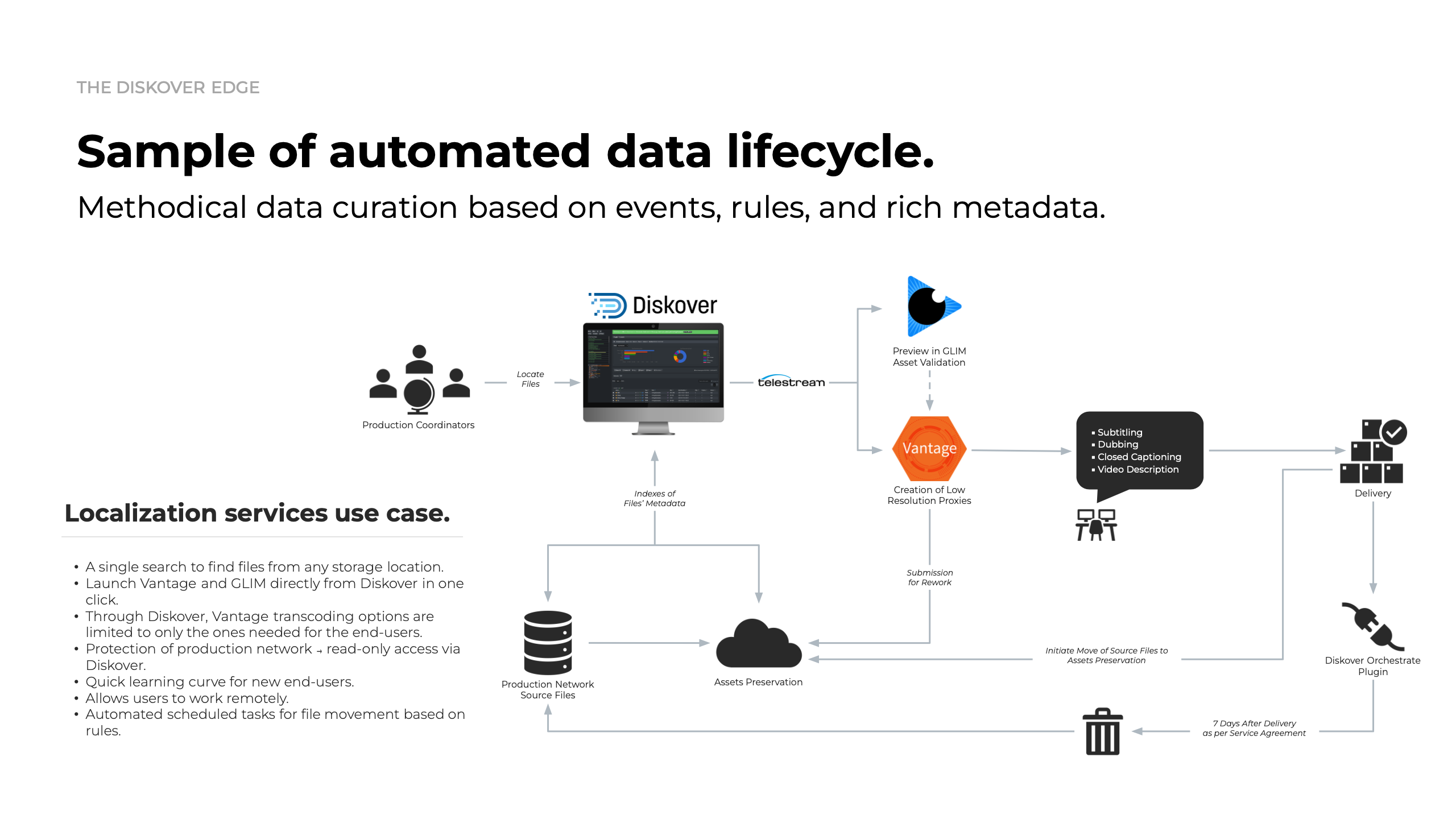
Diskover data mobility.
Diskover transforms unstructured chaos into orchestrated intelligence. Through metadata-driven indexing, tagging, and automation, it ensures the right data moves at the right time—fueling lifecycle management, analytics, and AI pipelines.
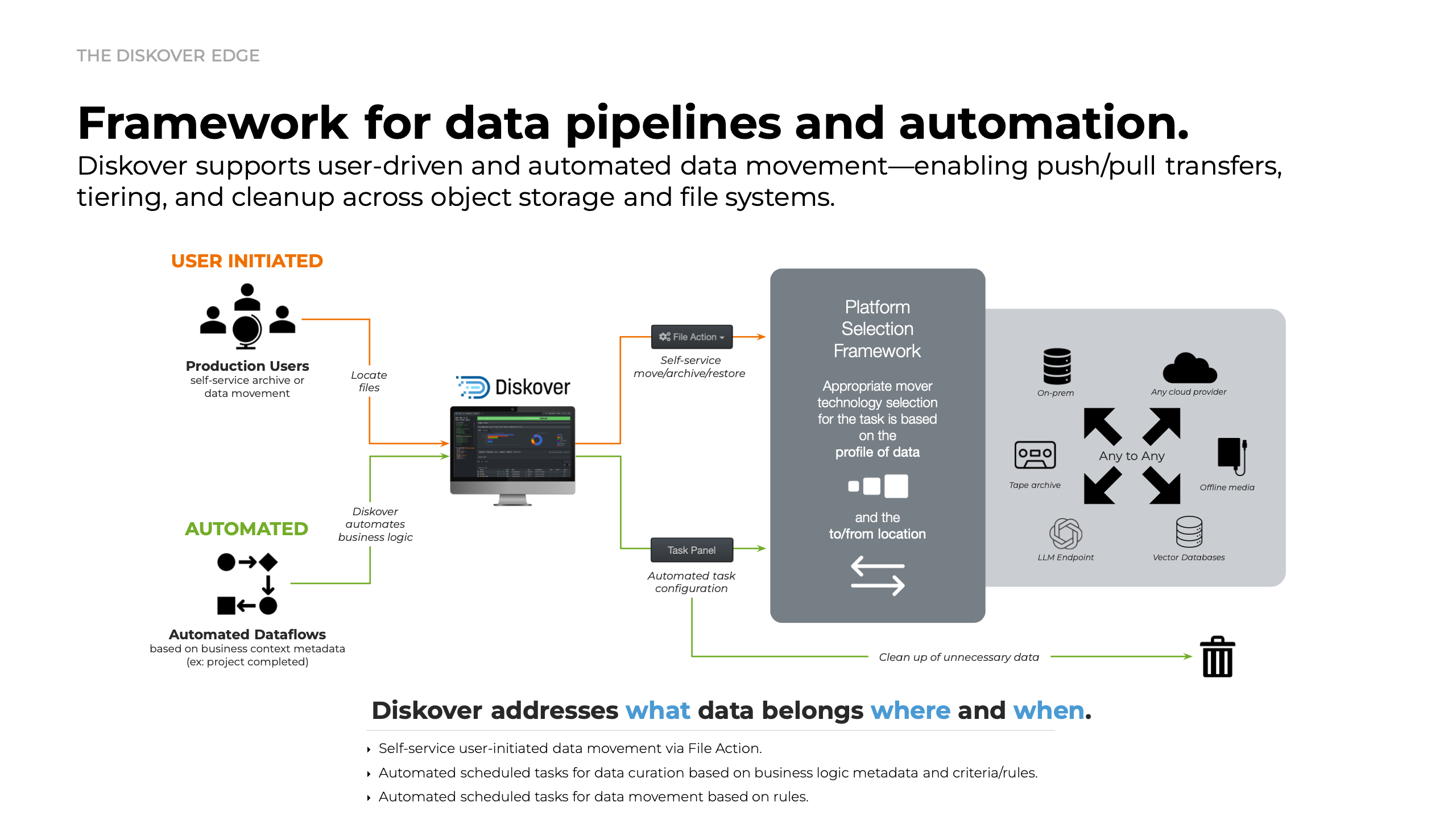
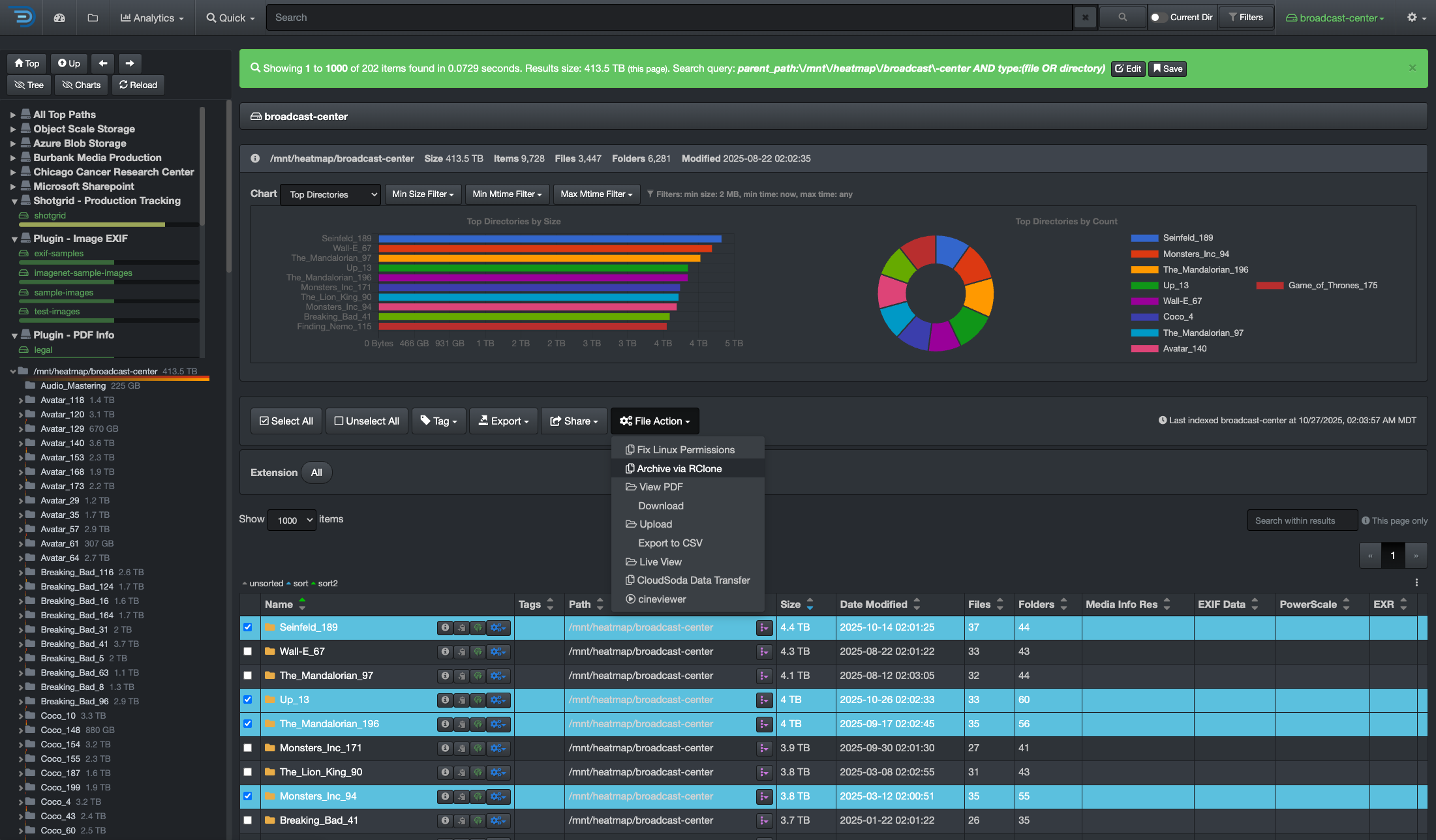
CloudSoda data mobility.
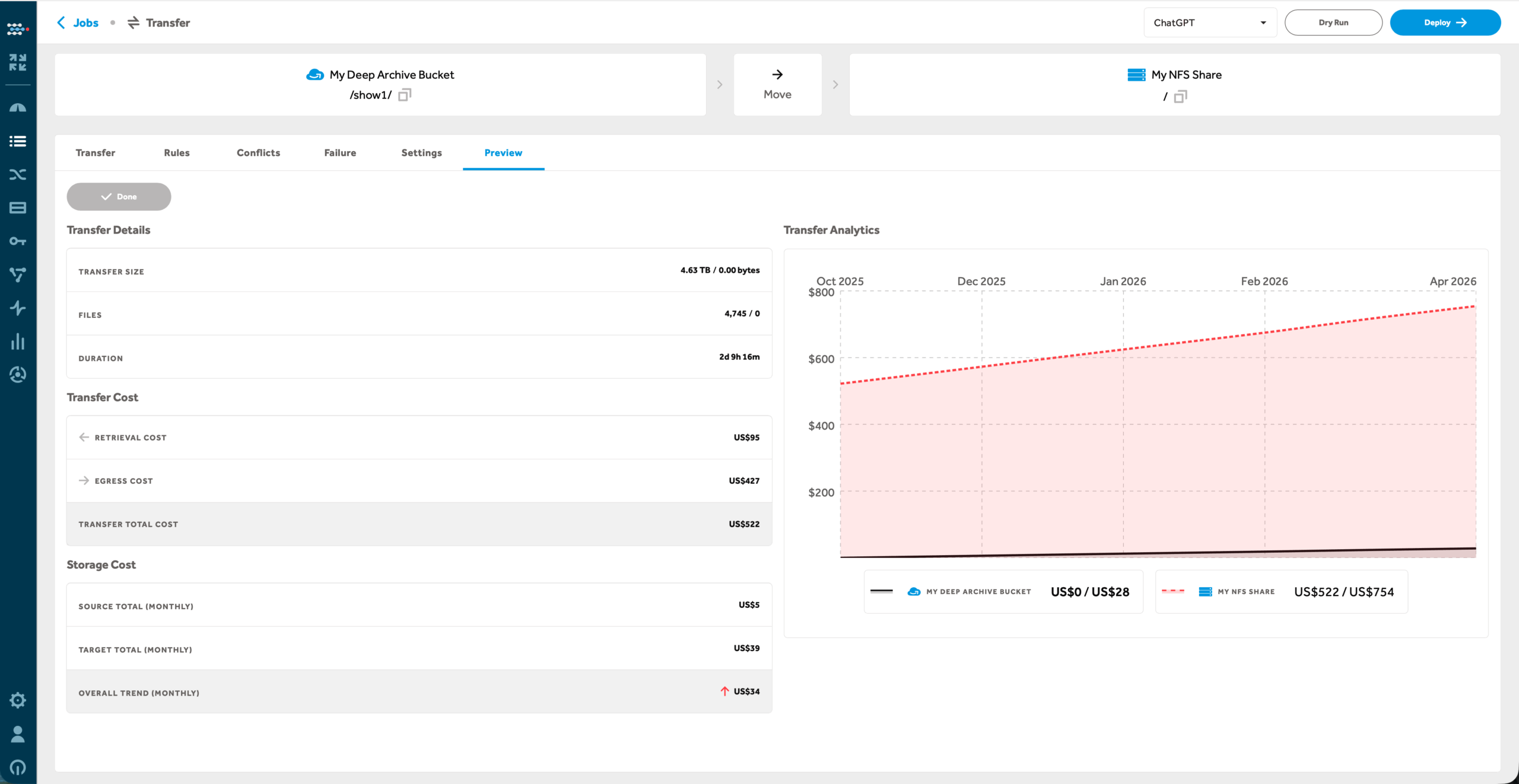
CloudSoda data mover orchestrates mobility across any environment—organizing, preparing, and delivering data securely at speed and scale. With dry-run simulations, detailed logs, and high-performance transfers, it delivers precision you can trust—ensuring every move is fact-based, compliant, and cost-efficient.
Real-world data mobility impact.
These are the everyday moments where metadata-driven movement pays off—moving the right data to the right place at the right time, automatically or on demand, with full cost and compliance awareness.
Move less. Deliver more.
Teams waste time (and budget) moving entire datasets when only a small slice is actually needed—creating duplicates, egress fees, and storage sprawl.
Diskover uses metadata, tags, and policy rules to move only what’s relevant, route it to the right destination, and keep a traceable record—so projects move faster with lower cost and less chaos.
The right media on the right tier.
Studios often keep “yesterday’s hot” media on expensive storage because it’s hard to prove what’s still active, what’s duplicated, and what can safely move.
Diskover tags content by project, age, usage, and business context—then triggers policy-based moves to archive, object, or nearline tiers (and back when needed), reducing spend while keeping teams productive.
Deliver analysis-ready datasets.
Bioinformatics teams lose days tracking down the correct inputs, reference files, and outputs across shared storage—then re-copy data “just to be safe.”
Diskover links files by metadata (sample ID, pipeline step, owner, timestamps) and tags datasets for promotion to compute, retention, or archive—so the right data lands where it’s needed, with fewer reruns.
Fewer reruns. Faster time-to-market.
EDA teams lose time when the right run inputs, checkpoints, logs, and outputs aren’t where they’re needed—so debugging becomes a hunt across scattered storage and stale copies.
Diskover connects run artifacts with rich metadata and tags, then triggers policy-based movement to the right tier or workspace—so teams can pull the exact datasets they need faster, reproduce results with confidence, and reduce costly rework.