ELEVATE YOUR DATA LAKES AND LAKEHOUSES STRATEGY
From muddy data to clean inputs.
Most lakes and lakehouses aren’t built for unstructured data—slowing analytics, governance, and AI. Diskover adds structure, context, and control, turning raw repositories into high-value data that flows into downstream platforms.
Partners we’re diving in with.
Diskover optimizes what flows from your lake to your lakehouse.
If the lakehouse builds the structure around your data lake, Diskover fills it with clean, contextual, and organized data that your analytics, governance, and AI teams can actually use. It bridges the gap between raw storage and real intelligence—bringing order, traceability, and value to every file, everywhere.
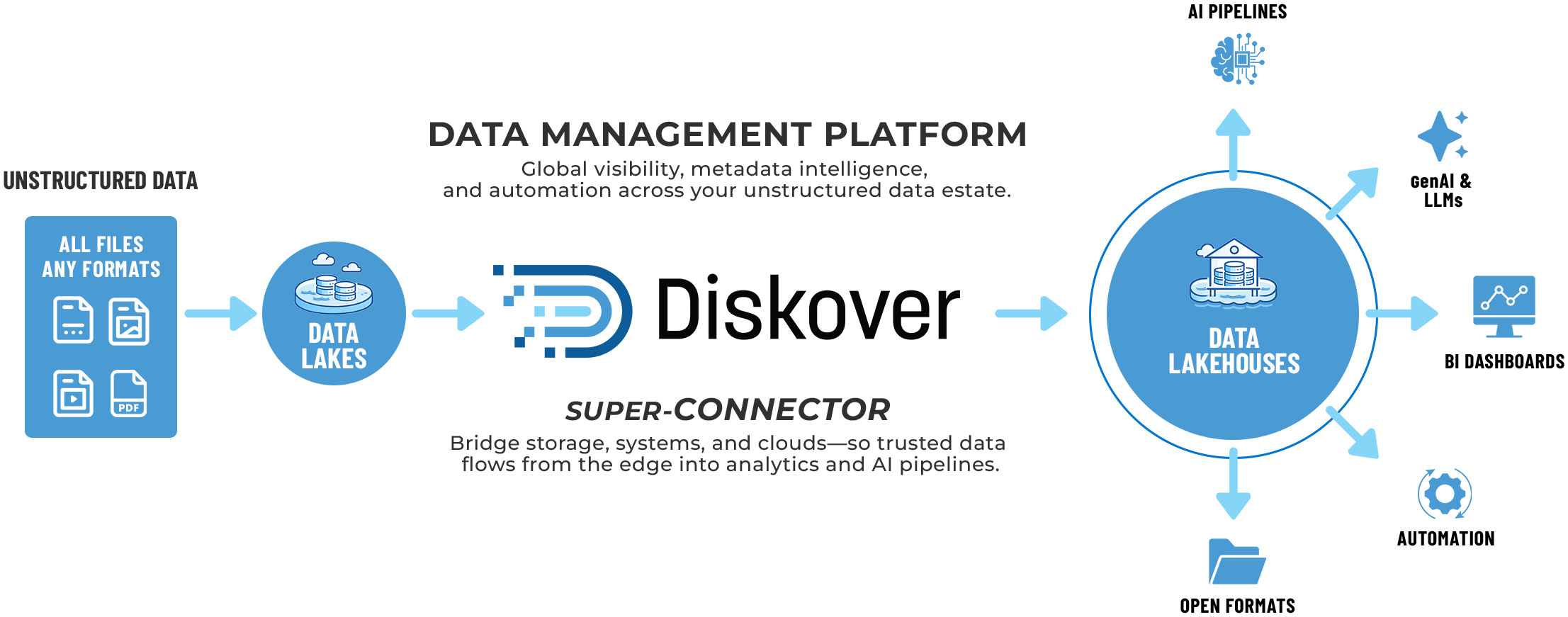
How it works and why it matters.
Built for real-world data complexity.
Unstructured data makes lakes muddy—hard to find, hard to trust, and expensive to manage. Diskover doesn’t just move or organize data—it enriches and curates it so only trusted, high-value data flows downstream.
AI/BI-ready dataset delivery.
Analysts waste days hunting files, validating versions, and rebuilding the same extracts.
Diskover identifies the “approved” sources, tags them with context (owner, project, sensitivity, freshness), and delivers a curated dataset to the lakehouse—ready for BI dashboards and AI pipelines.
Train models on trusted data.
RAG/LLM workflows ingest duplicates, stale content, and restricted files—leading to noisy answers and risk.
Diskover filters to high-value, policy-safe content, removes junk/duplicates, and passes only trusted documents + metadata (recency, permissions, lineage) into the lakehouse/vector pipeline.
Media & entertainment.
Teams can’t quickly find the right versions (proxy vs camera original), and expensive tiers fill up with old renders.
Diskover can classify assets by project/show/episode, identify cold data, and automate tiering, while sending only the needed working set into the lakehouse for reporting and workflow automation.
Life science & genomics.
FASTQ/BAM/VCF files are scattered, poorly labeled, and hard to trace back to sample/run metadata.
Diskover enriches files with lab/run/sample context, flags duplicate outputs, and delivers a clean, traceable dataset into the lakehouse for analytics and compliance-ready reporting.
Automotive & aerospace.
CAD, simulation, and test files sprawl across shares and cloud buckets, with duplicates and “final_v12” versions everywhere—making it hard to know what’s current and safe to use.
Diskover classifies and tags engineering data (program, part, revision, owner, sensitivity), flags duplicates and stale versions, and curates the approved “gold” dataset—then flows only trusted inputs into the lakehouse for analytics, AI, and compliance reporting.
Ready to bring order to your unstructured world?