DISKOVER PLATFORM—ARCHITECTED FOR EXTREME PERFORMANCE
Under the virtual hood—built for speed, scalability, and intelligence.
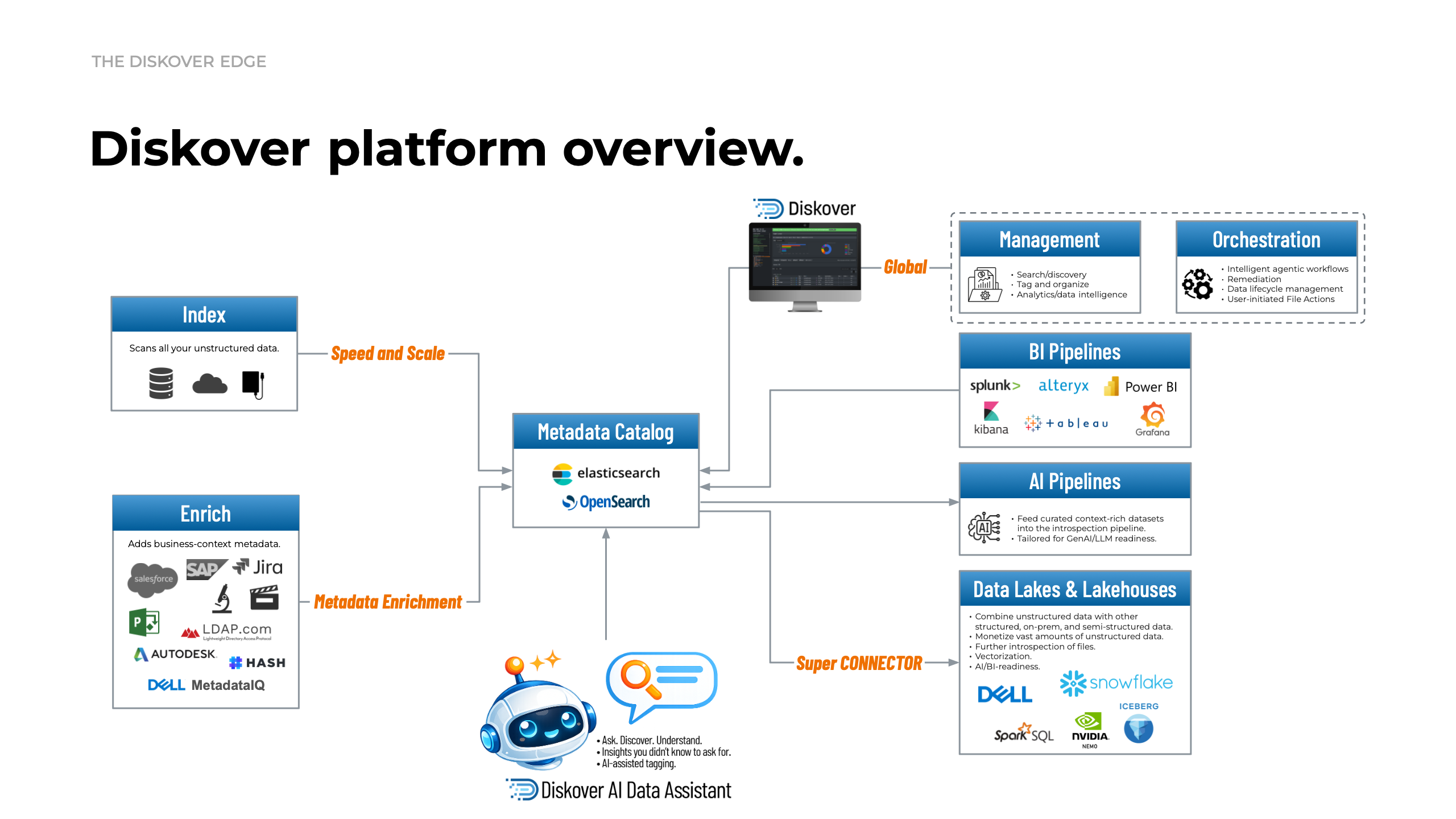
Diskover is designed for organizations drowning in unstructured data. It’s built to handle massive scale, helping teams quickly find files, understand what they have, and take action—no matter where their data lives. With speed and intelligence at its core, Diskover turns scattered storage into something clear, manageable, and ready for what’s next.
A modern foundation for clarity, control, and action.
The problem.
When files are spread across systems, locations, and clouds, finding what you need—or knowing what to do with it—becomes slow, expensive, and risky.
The solution.
Diskover solves this by creating a fast, scalable layer of intelligence on top of your existing storage. It connects to your filesystems, indexes metadata at speed, and gives you a clear, real-time view of what data you have, where it lives, and how it’s used.
Why it matters.
Less time hunting for data, lower storage costs, and data that’s ready for analytics, AI, and whatever comes next.

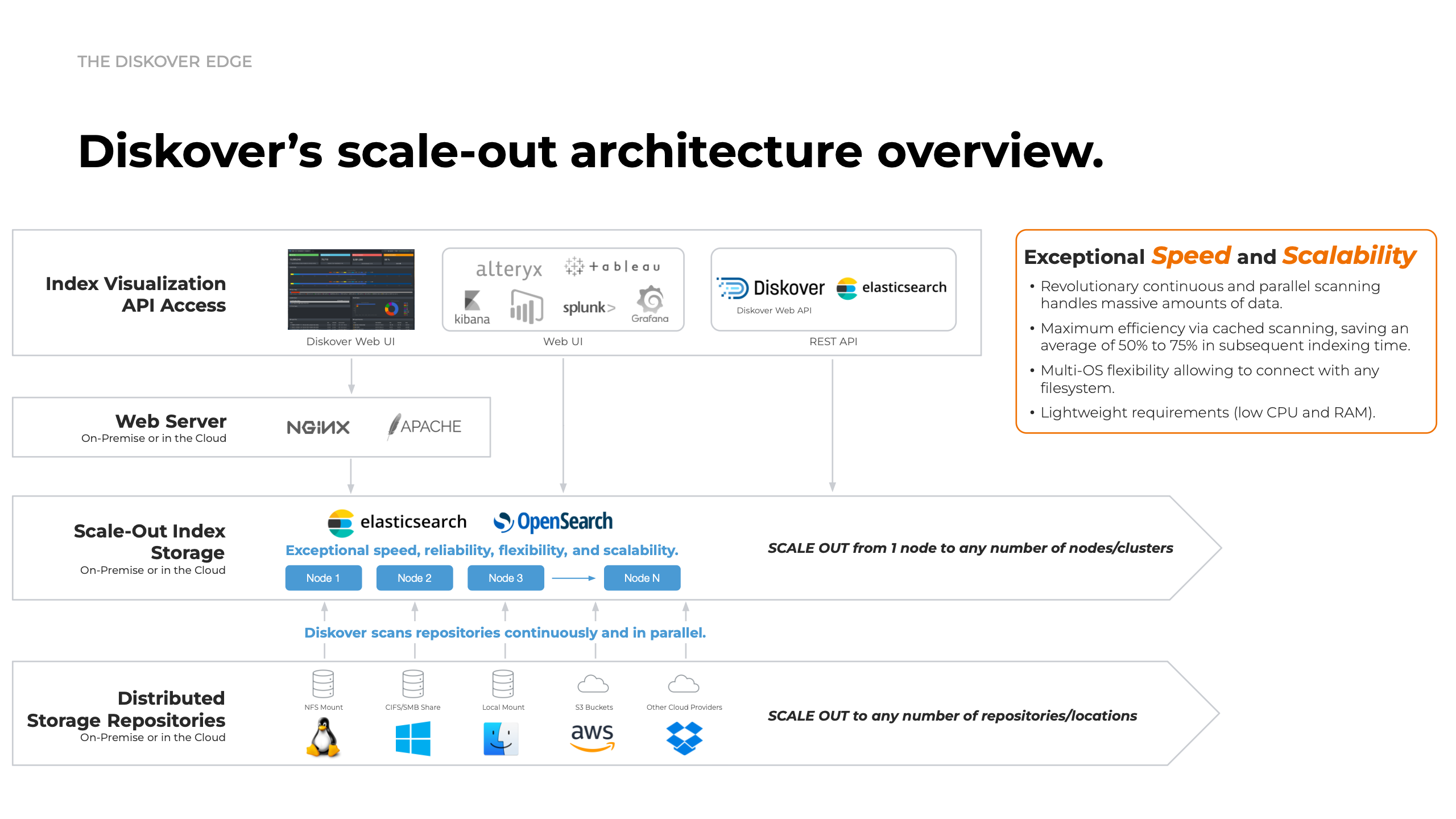
Supercharged indexing.
How it works.
Diskover scans your data in parallel, across many systems at once, using a distributed indexing engine built for scale.
Why it matters.
You can index massive environments faster, keep indexes up to date, and find any file in seconds—even as data keeps growing.
Storage and filesystem agnostic.
How it works.
Diskover connects to on-prem, cloud, and hybrid storage using scanners and plugins that work across different systems.
Why it matters.
You get one consistent view of all your data, without being locked into a single vendor or storage platform.
Optimized efficiency with cached scanning.
How it works.
Diskover reuses cached scan results instead of re-scanning everything from scratch.
Why it matters.
Re-indexing runs much faster and uses fewer resources—saving time, CPU, and cost in constantly changing environments.
Unified and enriched metadata catalog.
How it works.
Diskover combines core file metadata with enriched business and technical attributes into one searchable catalog.
Why it matters.
Your data becomes easier to find, understand, and act on—powering smarter decisions, automation, and analytics.
Secure real-time access to live data.
How it works.
Diskover can surface live filesystem changes between index runs through its Live View capability.
Why it matters.
You don’t have to wait for a full re-index to see what’s changing, reducing blind spots and unnecessary delays.
Built for data lakes and AI/ML/BI pipelines.
How it works.
Diskover prepares curated, metadata-rich datasets and integrates with data lakes, lakehouses, and analytics platforms.
Why it matters.
Analytics workflows stay current and consistent, ensuring high-value data delivers reliable, trustworthy results.
AI Data Assistant.
How it works.
Built on Diskover’s metadata foundation, the AI Data Assistant helps users explore data, ask natural questions, surface insights, and initiate supported actions directly from the platform.
Why it matters.
Teams move from search to insight to action faster—making confident decisions based on high-value data without needing deep technical expertise.
Additional details that make Diskover exceptional.
Made for modern enterprise reality.
Why it matters.
Are you ready to sustainably, affordably, and efficiently manage the lifecycle of all your data?
The power of open source and why it matters.
How it works.
Diskover is built on open-source technologies trusted for their performance and flexibility at enterprise scale. This foundation delivers instant search capability, limitless scalability, and seamless integration with modern data ecosystems such as Snowflake and Dell Data Lakehouse.
The result.
By combining open-source reliability with leading industry platforms, Diskover enables organizations to index, enrich, and orchestrate unstructured data wherever it resides—on-prem, in the cloud, or across hybrid environments.
Why it matters.
An open, transparent architecture means more trust, easier integration, and the freedom to adapt as your data strategy evolves. Diskover lets teams innovate faster without being boxed in by closed systems.
Built on openness, designed for longevity.
Ready to bring order to your unstructured world?