From Whiteboard to Workflow: How Diskover Built Its Openflow Connector for Snowflake
Summary of our recent article published on the Snowflake Medium blog
When Diskover partnered with Snowflake, one of the earliest engineering priorities was clear: build a scalable, low-code pipeline to stream unstructured file metadata and storage analytics directly into Snowflake. That challenge became the foundation of the Diskover Openflow connector, designed by engineer Byron Rakitzis, and it’s now emerging as a powerful new ingestion path for enterprises preparing their data for AI.
Why Openflow?
Traditional ingestion methods rely on custom-built JDBC connectors – flexible, but difficult to scale, maintain, and deploy. Diskover needed a different approach. Snowflake Openflow provided a low-code, processor-driven framework that handled much of the orchestration behind the scenes, while Kafka acted as the durable, future-proof transport layer.
This allowed Diskover to:
- Scale ingestion without custom code, using Openflow’s built-in orchestration
- Standardize on Kafka, enabling future expansion to other warehouses with Kafka consumers
- Accelerate onboarding, even for customers without deep engineering teams
What the Pipeline Handles
Diskover’s connector processes two major data flows:
- Quota records: storage allocation and usage over time
- File metadata: billions of filenames, paths, timestamps, sizes, and owners indexed by Diskover
Openflow organizes these flows into parallel branches on the canvas, separates metadata-only records from those requiring additional handling, and streams the results into Snowflake using Snowpipe Streaming.
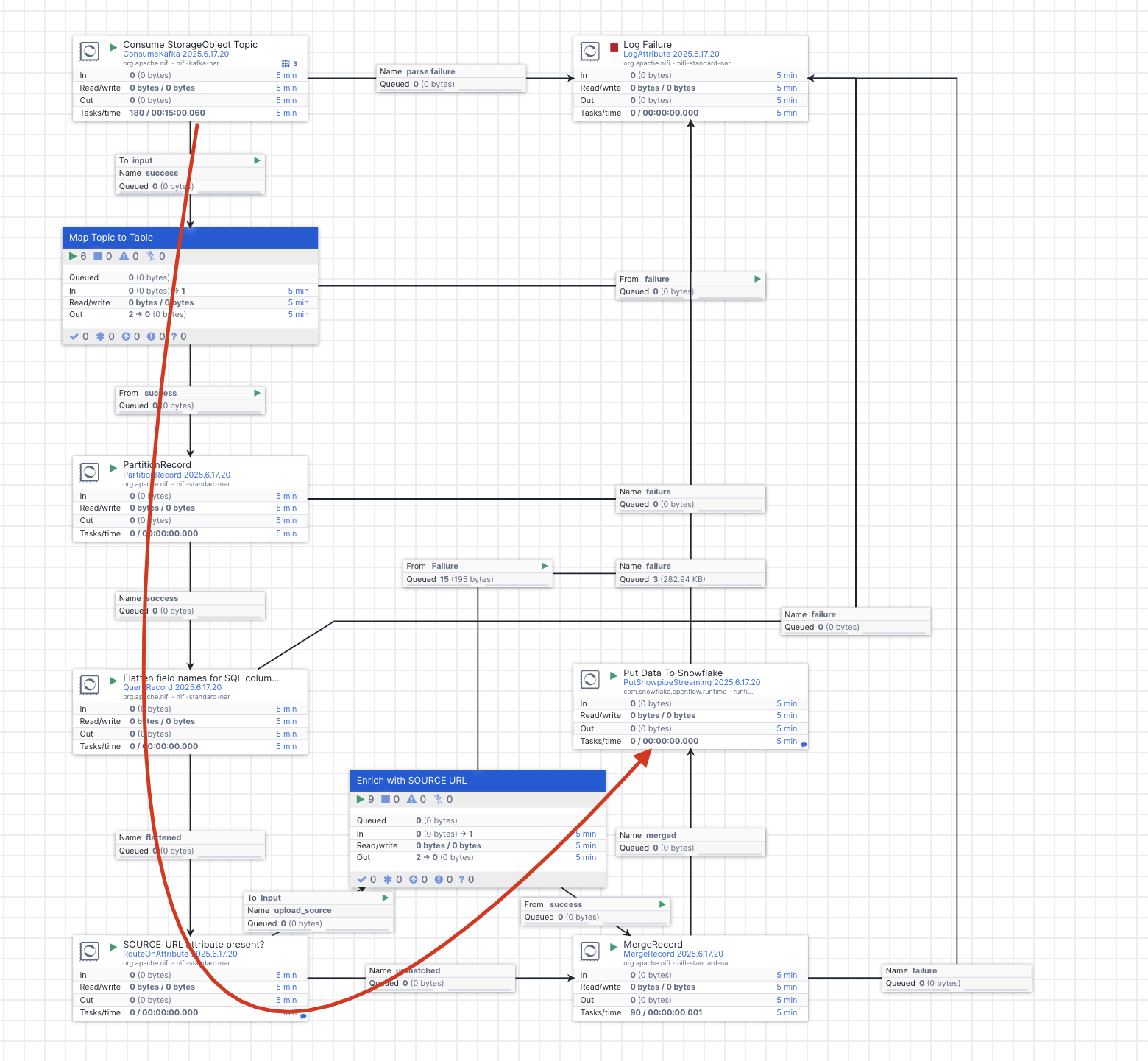
Lessons Learned While Building It
As Byron built the first working version, a few themes emerged:
- Low-code still requires engineering discipline.
- Each processor needs careful configuration – thread counts, schemas, partitioning strategies. The visual workflow hides orchestration, but not design responsibility.
- Error messages can be…cryptic.
- Some Openflow errors were vague or misleading. Debugging often required digging into SQL roots or using AI tools to interpret internal messages.
- Scaling is about design, not just settings.
- Kafka partitioning proved essential. Too few partitions bottleneck the pipeline; too many add overhead. Openflow helps surface bottlenecks, but thoughtful upfront design matters most.
- Automate everything possible.
- To avoid manual copy-paste errors across dozens of processors, Byron built a Go-based code generator to produce consistent JSON, SQL, and YAML configs, a key step toward repeatability.
Practical Advice for Teams Considering Openflow
- Start small and iterate. Build a functional pipeline before stressing it with scale.
- Leverage the Apache NiFi community. Openflow concepts closely follow NiFi, and existing documentation is invaluable.
- Automate configs early. Avoid manual parameter editing at all costs.
- Expect tuning and refinement. Openflow accelerates development, but production pipelines still require thoughtful engineering.
What’s Next
The connector is fully functional today, with beta deployments beginning soon. These real-world environments will answer open questions around autoscaling, throughput, and handling more complex metadata or blob-level extraction.
Long term, the architecture positions Diskover to extend similar pipelines to other cloud warehouses, because Kafka remains at the core, the pipeline can evolve without major redesign.
The full Medium article includes deeper technical detail, pipeline visuals, snippets from our engineering interview with Byron, and a look at what’s ahead.
Want to Learn More?
See how Diskover is partnering with Snowflake and powering AI-ready unstructured data pipelines.