PLUGINS ECOSYSTEM
Supercharged tools for limitless innovation.
Diskover’s open-source infrastructure provides unparalleled extensibility, allowing plugins to be developed by Diskover, third parties, or even end users to address specific requirements.
Our comprehensive data management solution features a diverse array of integrated, configurable tools, with many more under development. One standout feature is file action, which enables authorized users to execute file operations—directly from the user interface. This capability streamlines workflows, enhances efficiency, and ensures greater control over data management processes.
PLUGINS FOR METADATA CATALOG ENRICHMENT
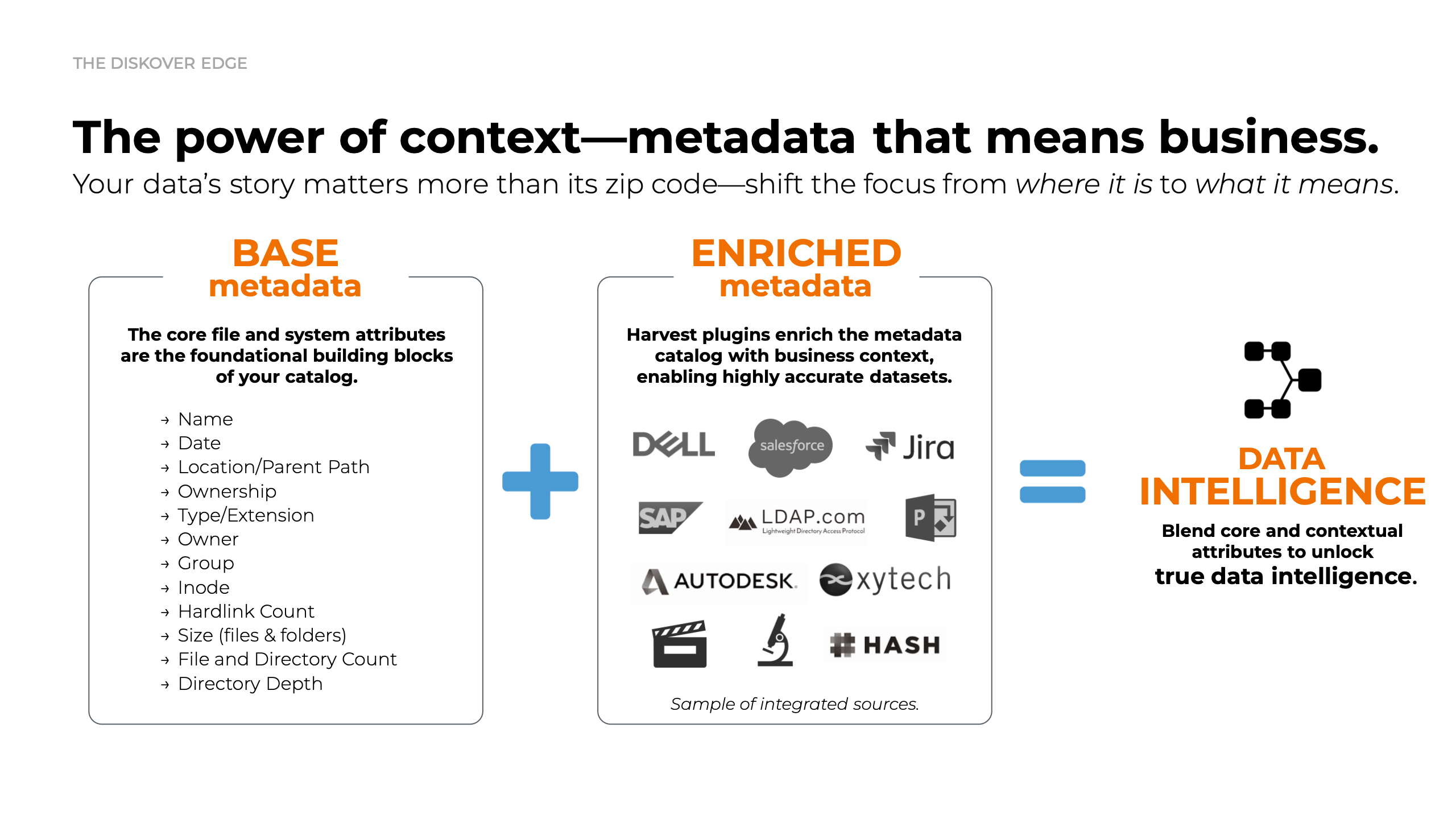
Metadata enrichment.
Diskover sets the standard in the data management market with its extensive range of metadata harvest plugins, which enrich data with a comprehensive set of attributes.
This business-context metadata is an invaluable asset for locating, organizing, and analyzing specific data, as well as for designing workflows tailored to precise data management tasks. To ensure optimal performance, these plugins can be executed post-indexing and at scheduled intervals, preserving the rapid speed of regular indexing while still providing detailed metadata insights.
LIFE SCIENCE
BAM
Collects rich metadata from BAM (Binary Alignment Map) and SAM (Sequence Alignment Map) files for bioinformatics workflows. Learn more →
CORE
Breadcrumb
Captures directory and project lineage metadata to help trace file origins, movement, and relationships across storage environments.
CORE
Cost
Applies storage cost per GB to files and directories, enabling detailed cost analysis and reporting across the index at scale. Learn more →
CORE
Dell PowerScale
Adds rich PowerScale-specific metadata to the index, allowing deeper visibility into file system details and storage behavior. Learn more →
CORE
Dell SmartPools
Adds rich SmartPools-specific metadata to the index, allowing deeper visibility into file system details and storage behavior. Learn more →
CORE
Dell Quota
Adds Dell Quota metadata to the index for visibility into storage limits, usage tracking, and quota management across your data estate.
CORE
File Kind
Groups file types into user-defined categories and adds metadata during indexing to support tagging, filtering, and reporting workflows.
CORE
First Index Time
Captures the file’s initial arrival time when first detected by Diskover and stores it as extra metadata during the indexing process.
CORE
Hash Values
Generates and stores file hash values (xxhash, md5, sha1, sha256) for integrity checksums, de-duplication, and virtual fingerprinting.
CORE
Image Info
Extracts and indexes EXIF metadata from image files, including camera settings, date taken, GPS coordinates, and other technical capture details. Learn more →
MEDIA
Media Info
Adds searchable metadata to media files, such as resolution, codec, and pixel format, supporting automation, curation, and deep analysis. Learn more →
MEDIA
OpenEXR Info
Extracts metadata from OpenEXR image files, enabling detailed insight and searchability for high-dynamic-range image content. Learn more →
CORE
Path Tokens
Breaks down file and folder names into searchable tokens, making it easier to filter, group, and analyze data by path structure.
CORE
PDF Info
Extracts and indexes key metadata fields from PDF files, including title, author, creation date, and document modification history.
MEDIA
ShotGrid
Harvests detailed production status metadata from Autodesk Flow Production Tracking for deep visibility, analysis and workflows. Learn more →
CORE
Unix Permissions
Captures Unix permission attributes for all files and directories, tagging items with fully open permissions to support audits and access reviews.
CORE
Windows Attributes
Adds Windows file ownership and DACL permissions to files and directories, supporting security audits and access control visibility in Elasticsearch.
CORE
Windows Owner
Captures Windows file owner and primary group metadata for each file and directory, enabling visibility into access and ownership patterns.
MEDIA
Xytech Asset Creation
Identifies rehydrated assets from LTO and removable drives, adding asset IDs and business context for correlation and discovery. Learn more →
MEDIA
Xytech Order Status
Correlates Xytech order data with file metadata in Diskover, enabling granular automation, reporting, and search. Learn more →
PLUGINS FOR SUSTAINABLE DATA MANAGEMENT
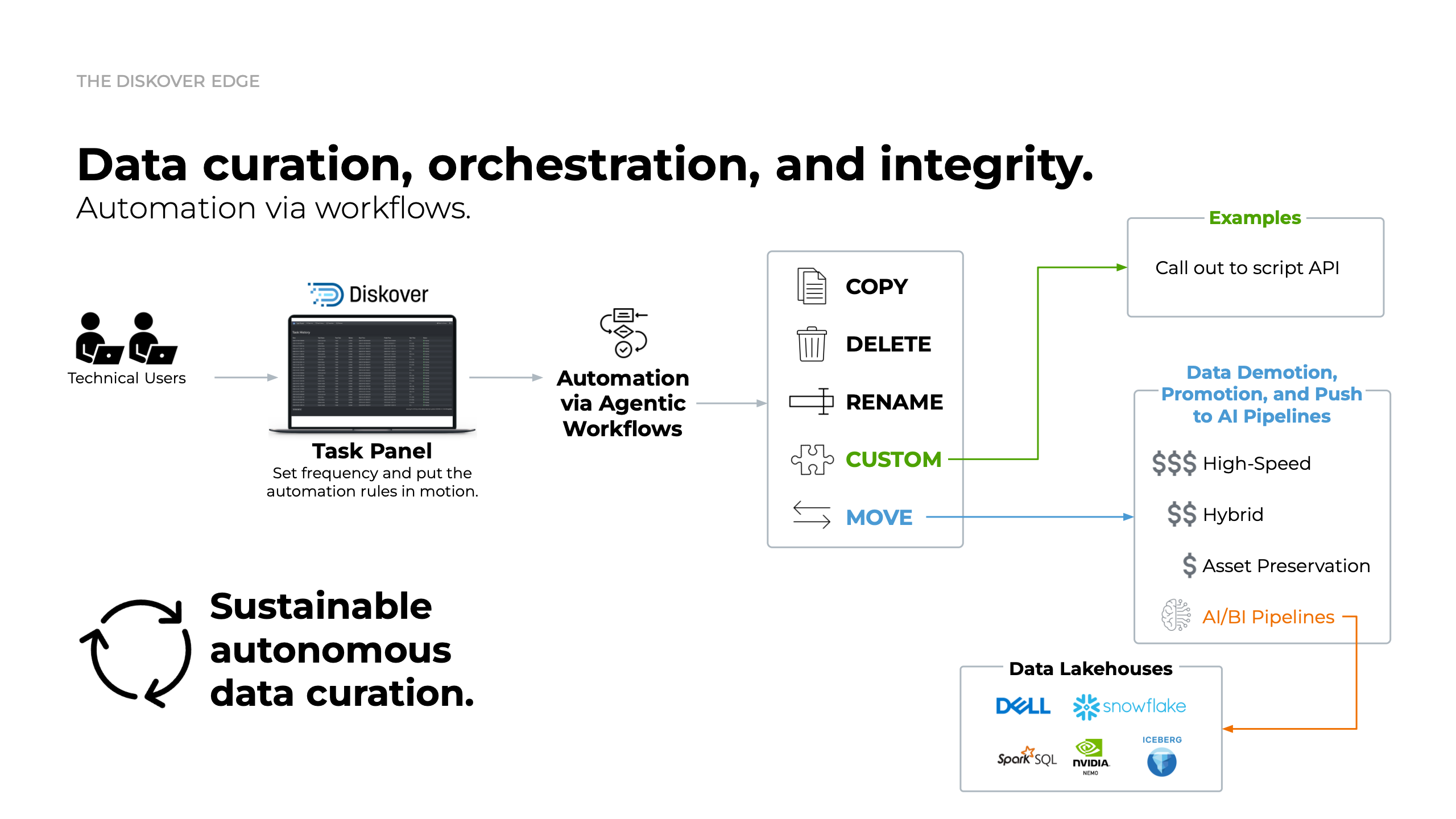
Orchestration and integrity.
Diskover’s plugins are essential for sustainable data management, providing both manual and automated tools that streamline cleanup, organization, and long-term optimization. By supporting a wide range of use cases, they help ensure your data environment stays healthy, cost-effective, and compliant—whether you’re automating routine maintenance or managing complex workflows.
Creating data is expensive, and recreating lost or corrupted data can be even costlier. From preserving data integrity to reducing costly errors, these plugins deliver peace of mind. They validate files, identify issues like illegal characters or overly long names, and safeguard against data loss or corruption. With Diskover’s plugin ecosystem, your data remains accurate, searchable, and ready for whatever’s next.
CORE
Orchestrate
Executes policy-driven remediation, movement, copy, delete, rename, or custom actions on files or directories. Learn more →
CORE
AutoTag
Automatically applies tags to files and directories using rule-based logic powered by file metadata and business context. Learn more →
CORE
Duplicates Finder
Identifies duplicate files using hash values (xxhash, md5, sha1, sha256) across indices to support cleanup, compliance, and deduplication workflows.
CORE
Hash Differential Checksums
Validates file integrity after transfers by comparing source and destination hash values, detecting corruption and generating a manifest. Learn more →
CORE
Illegal & Long Filename
Detects illegal characters or excessive filename lengths, tagging non-compliant entries and optionally applying automated remediations. Learn more →
CORE
Index Differential
Compares two indices to detect file-level differences over time or between systems, generating a CSV for review, sync, or audit workflows.
PLUGINS FOR DATA MOVEMENT
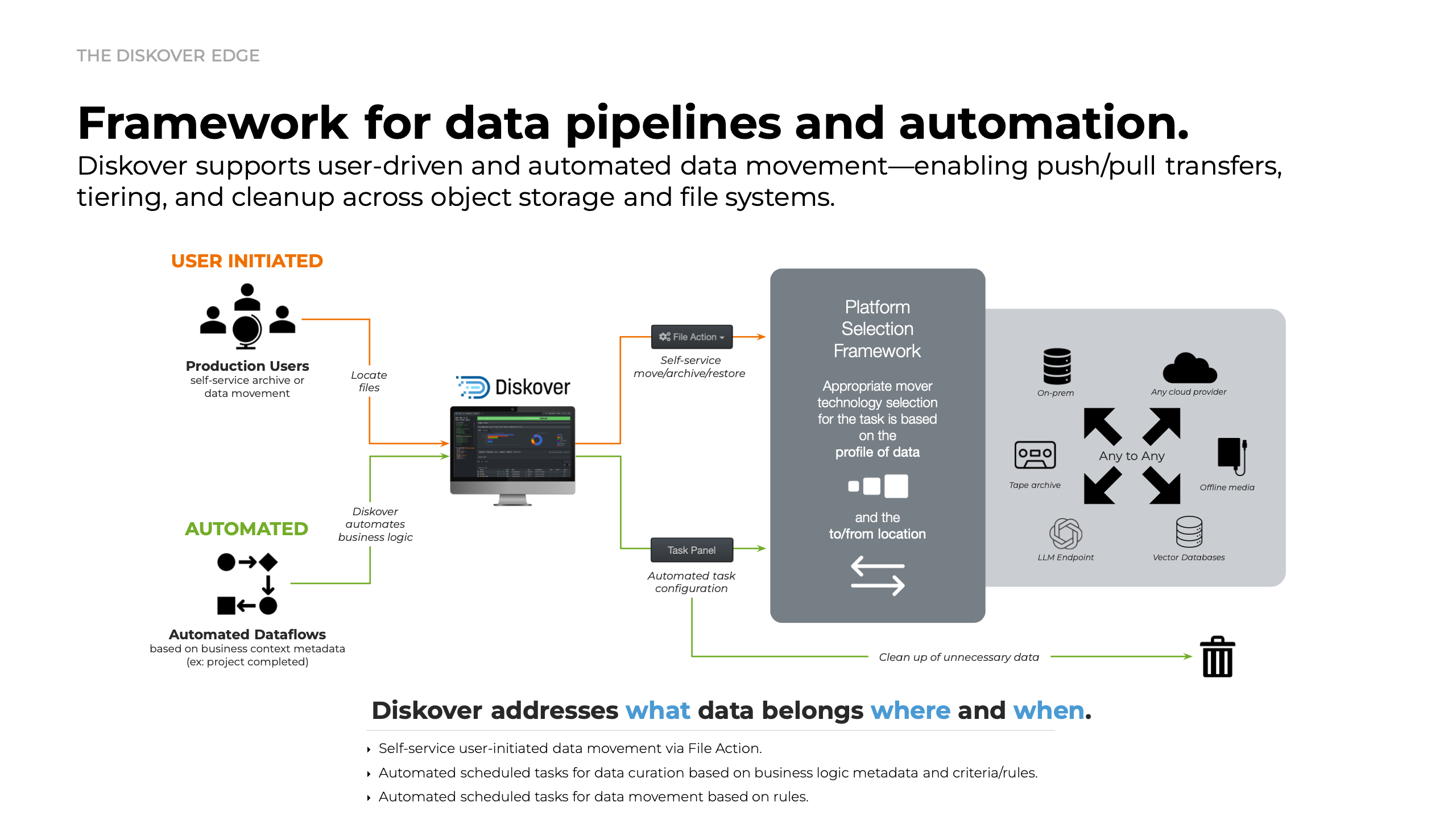
Data mobility.
These plugins could easily fall under both data curation and file actions; however, the rapid growth of our plugin library and increasing demand for specialized tools have inspired us to create a dedicated category. This distinction highlights their significance and reaffirms our commitment to meeting the evolving needs of our users in data optimization and organization.
These plugins play a pivotal role in optimizing data placement and timing, ensuring that data is stored where it’s most needed, precisely when it’s needed—while eliminating unnecessary storage overhead.
CORE
CloudSoda Data Mobility
Securely moves data between any storage location, enabling fast and secure data sharing while optimizing performance and minimizing costs.
CORE
Dell SmartSync
Leverage Diskover’s deep metadata insights to identify high-value or low-use data, then trigger targeted actions—replicate, tier, or relocate. Learn more →
CORE
Ngenea Data Orchestrator
Enables secure, policy-driven data movement from Diskover to cloud, object, NAS, or tape storage based on value, usage, and cost. Learn more →
CORE
Qumulo Data Mover
Facilitates fast, secure transfers between Qumulo and AWS directly from Diskover, supporting hybrid workflows and storage flexibility. Learn more →
CORE
Rclone Data Mover
Enables scheduled or on-demand data movement via Rclone, using predefined source/destination profiles and flexible criteria from within Diskover.
CORE
Vcinity High-Speed Transfer
Supports high-speed data movement across any NFS, SMB, or S3 storage, triggered on-demand or via automated workflows inside Diskover. Learn more →
PLUGINS FOR USER-INITIATED ACTIONS
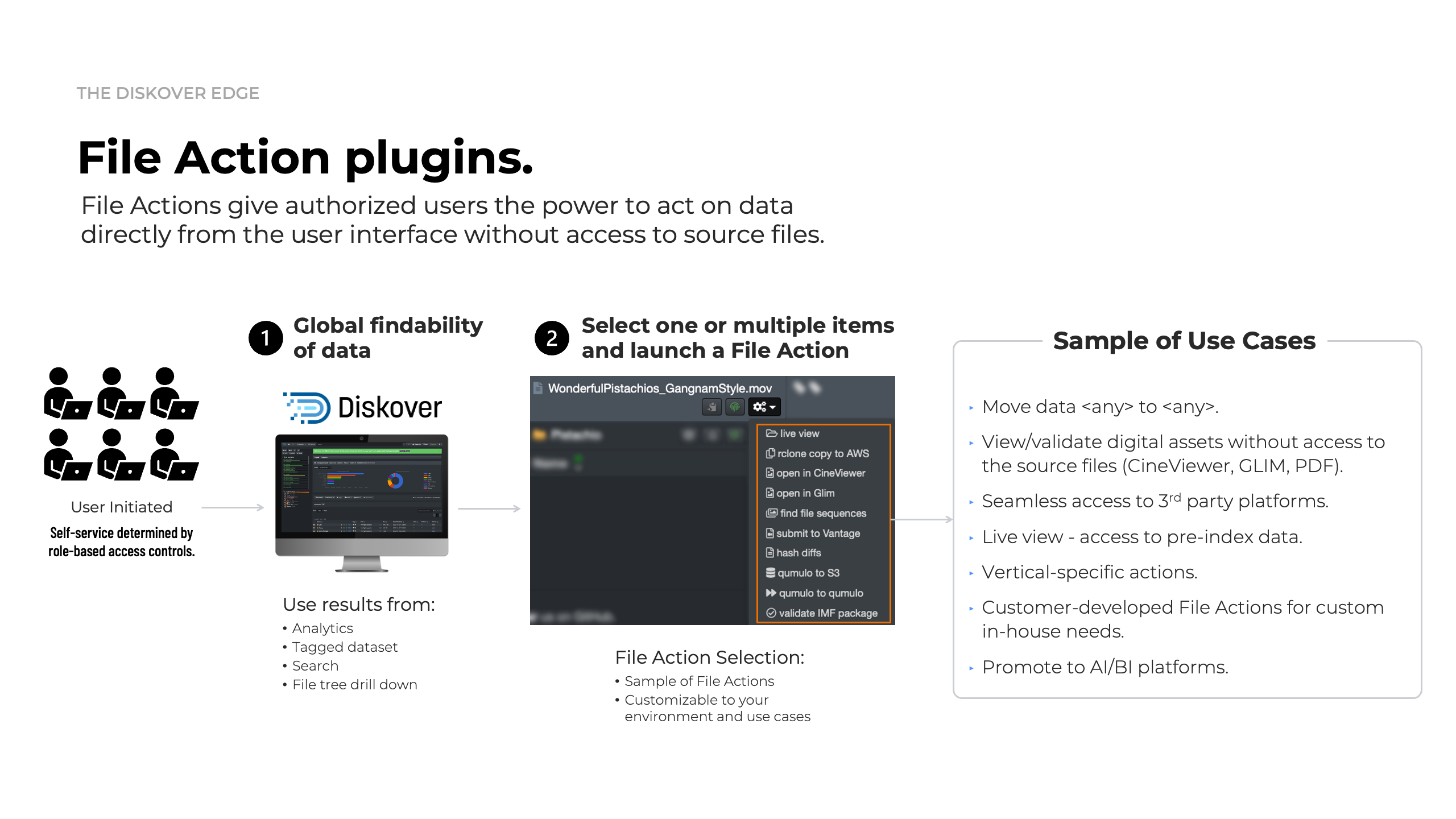
File actions.
Authorized users, following role-based access controls, can initiate File Actions directly from the Diskover interface, supporting a wide range of use cases.
Whether it’s taking targeted actions on data or seamlessly integrating with third-party platforms, Diskover’s open-source architecture empowers users to develop custom File Action Plugins, enabling the automation of unique in-house workflows with ease and flexibility.
MEDIA
CineViewer Player
Securely streams high-resolution media for review, enabling validation without exposing source files or compromising your production network. Learn more →
MEDIA
EDL Check & Download
Facilitates fast, secure transfers between Qumulo and AWS directly from Diskover, supporting hybrid workflows and storage flexibility.
CORE
Export
Enables authorized users to preview and export formatted CSV files for integration with external tools and workflow automation systems.
MEDIA
Find File Sequences
Identifies and lists file sequences in a directory based on a single reference file, simplifying sequence management and referencing. Learn more →
CORE
Fix Unix Permissions
Allows authorized users to reset Unix permissions on selected files or directories to a configured, compliant permission value.
LIFE SCIENCE
Grant
Enables grant-based metadata tagging and dataset curation for research compliance, access control, and cost tracking. Learn more →
MEDIA
IMF Change Report
Generates human- and machine-readable reports (EDL) that identify IMF image changes and reference updated media for review or automation.
CORE
Live View
Provides real-time visibility into a filesystem between indexing intervals, enabling authorized users to monitor changes as they happen.
CORE
Make Links
Allows authorized users to create symbolic or hard links for selected files and directories directly from the Diskover interface.
CORE
PDF Viewer
Allows authorized users to safely view and validate PDF files, in-browser and directly from Diskover, without direct access to the original source files.
CORE
Spectra
Securely queries the Spectra API on demand to check detailed tape status, including whether media is in the library or on the shelf.
MEDIA
Telestream GLIM Media Viewer
Enables safe media playback directly from Diskover, without exposing source files or compromising your production network. Learn more →
MEDIA
Telestream Vantage
Enables users to submit files for Telestream Vantage transcoding directly from the Diskover interface using File Actions. Learn more →
MISCELLANEOUS PLUGINS
Everything else.
CORE
Grafana & Grafana Cloud
Creates time-based summary indices in Elasticsearch for directory size and count metrics, enabling rich data visualization in Grafana or Grafana Cloud.
GET STARTED
Ready to manage your data everywhere from anywhere?